从零开始,学会数据清洗的秘诀
在大数据时代,数据被誉为“21世纪的石油”,而数据的质量决定了它的价值。原始数据通常包含大量的噪音、不完整或错误的信息,直接使用这样的数据可能导致分析结果不准确,甚至是错误的决策。因此,数据清洗作为数据处理的关键步骤,能够显著提升数据的质量,为后续的数据分析、机器学习建模等提供可靠的基础。这篇文章将从零开始,详细介绍数据清洗的步骤、工具和策略,帮助你掌握这项数据分析中的核心技能。无论你是初学者还是有经验的分析师,都能通过本文学会如何高效地进行数据清洗,并借助DataFocus等工具提升工作效率。

数据清洗的重要性
数据清洗是数据处理流程中的基础环节,其目的是确保数据的准确性、一致性和完整性。清洗后的数据不仅能更好地反映实际情况,还能提高分析和建模的效果。在企业的数据分析和决策过程中,干净的数据能够减少偏差,提升决策的科学性,从而直接影响业务表现。因此,掌握数据清洗的技巧,对于任何数据工作者来说都是必不可少的。
当我们面对庞大的数据集时,可能会遇到许多常见问题,包括重复数据、缺失值、异常值、格式不一致等。这些问题不仅影响分析结果,还会耗费大量时间和精力。因此,学会快速、有效地识别并解决这些问题,将使你的数据处理工作事半功倍。
数据清洗的核心步骤
在进行数据清洗之前,必须明确处理的目标和要求。以下是数据清洗的一般步骤:
-
识别与处理缺失数据
数据缺失是常见问题之一,可能是由于系统故障、人工录入错误或数据传输不完整等原因造成的。处理缺失数据的方式有多种,包括删除缺失数据、用平均值或中位数填补、以及通过预测模型补全数据。每种方法都有其适用场景,必须根据具体情况选择最合适的处理方式。借助像DataFocus这样的智能工具,可以轻松检测并处理大规模数据集中的缺失值。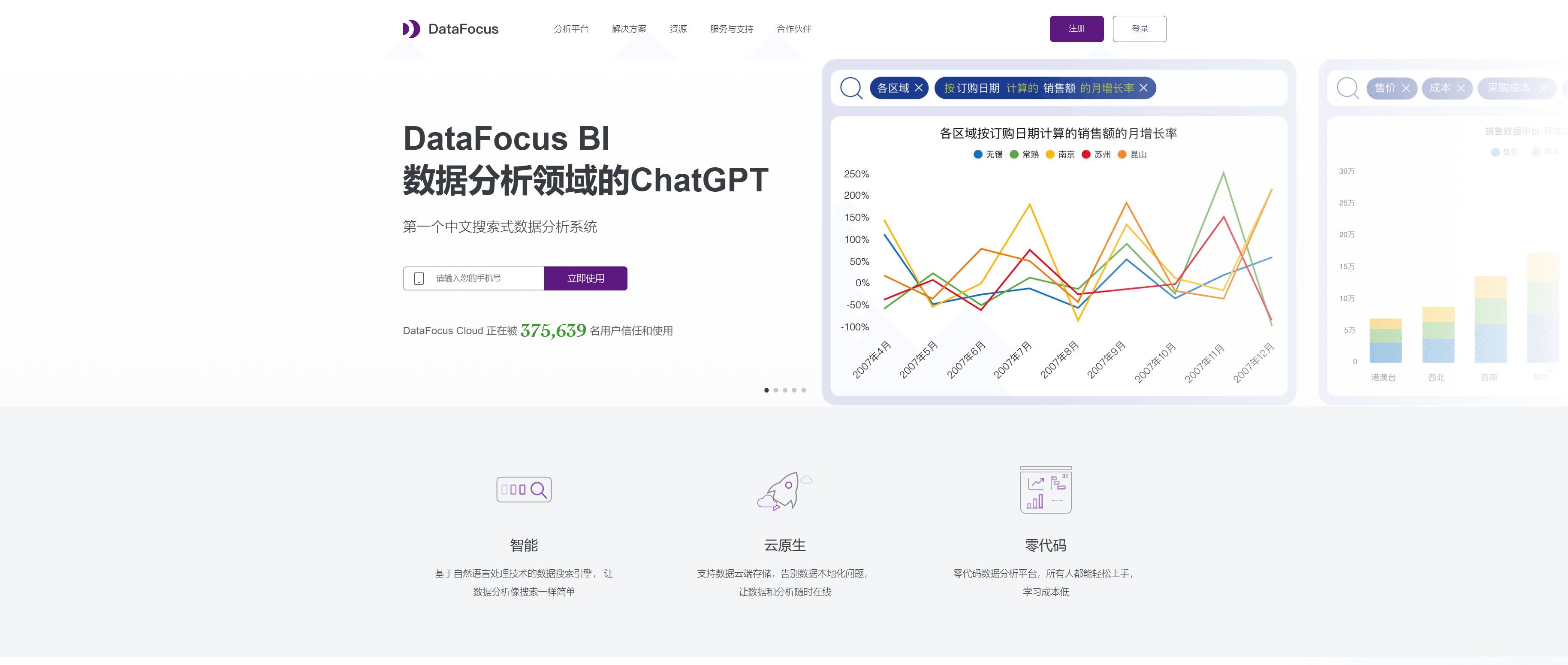
-
处理重复数据
重复数据是由于多次录入或系统同步错误等原因造成的。重复数据不仅会占用存储空间,还会影响数据分析的准确性。为了确保数据的唯一性,通常需要通过筛选、聚合等方式去除重复数据。通过DataFocus这样的工具,能够快速扫描数据集,识别并删除重复项,确保数据的唯一性和准确性。 -
格式规范化
数据的格式一致性对于后续的分析和处理至关重要。不同来源的数据可能存在格式差异,如日期格式、货币单位、地址信息等。因此,需要对数据进行格式规范化处理,确保所有数据以统一标准进行存储和使用。DataFocus提供了丰富的格式化工具,能够快速对数据进行统一处理,使其符合标准规范。 -
异常值检测与处理
异常值是指数据集中的极端值,这些值可能是由于录入错误、设备故障等原因引起的,通常不符合实际情况。在处理异常值时,可以选择剔除它们,也可以通过统计方法或机器学习模型进行平滑处理。通过DataFocus中的异常值检测功能,能够快速识别数据中的极端值,并提供多种处理方案,以确保数据的可靠性。
-
数据一致性检查
数据一致性是指数据集中的各个字段和记录之间是否相互匹配。例如,一个人的出生日期不能晚于其注册日期。通过一致性检查,可以确保数据的逻辑合理性和完整性。DataFocus能够自动进行一致性检查,确保所有数据项相互匹配并符合业务逻辑。
数据清洗的常用工具
除了手动清洗数据,借助一些高效的工具和平台,可以大大提高数据清洗的效率。以下是几种常用的数据清洗工具:
-
DataFocus
DataFocus是一款集数据清洗、分析、可视化于一体的智能化工具。它不仅能够自动识别数据中的缺失值、重复项和异常值,还提供了丰富的处理方案,帮助用户快速清理并规范数据格式。DataFocus的界面友好,操作简便,适合各种层次的数据分析人员使用。DataFocus还支持一键导入、导出数据,能够与其他数据分析工具无缝对接,极大地提升了工作效率。 -
OpenRefine
OpenRefine是一款免费且开源的数据清洗工具,广泛应用于大规模数据集的清洗和转换。它支持多种格式的数据导入,并提供了强大的文本处理功能,适合复杂的文本数据处理需求。OpenRefine还支持通过自定义规则进行数据清洗,是数据分析师的得力助手。
-
Trifacta Wrangler
Trifacta Wrangler是一款专门用于数据清洗和准备的工具,提供了强大的数据可视化和清洗功能。该工具可以自动检测数据中的问题,并提供相应的清洗建议,用户可以根据实际需求进行调整。Trifacta还支持机器学习算法,能够根据历史清洗记录优化清洗过程。
高效数据清洗的策略
为了提高数据清洗的效率,我们需要遵循一些有效的策略:
-
明确清洗目标
在数据清洗之前,必须明确清洗的目标是什么。这意味着我们需要清楚知道哪些数据是必须的,哪些数据是无关紧要的。这样可以避免在不必要的数据上浪费时间和资源。 -
分阶段进行数据清洗
面对大规模的数据集时,可以将清洗过程分为多个阶段进行。例如,首先处理缺失值,然后再进行重复数据的处理,最后进行格式规范化和异常值处理。分阶段的方式可以让清洗过程更加有条不紊,并有助于逐步检查每个环节的清洗效果。 -
借助自动化工具
尽可能使用自动化工具来完成重复性高的任务。例如,DataFocus可以帮助自动检测缺失值和异常值,并提供一键式处理功能。通过自动化工具,不仅可以节省大量时间,还能减少人为错误。 -
定期进行数据审查
数据是动态变化的,因此数据清洗不仅仅是一次性任务。在数据处理的不同阶段,定期进行数据审查,以确保数据保持高质量,是至关重要的。通过定期清洗,可以避免数据随着时间的推移而积累问题,保持分析结果的准确性。
总结
数据清洗作为数据处理中的关键步骤,直接决定了后续分析和决策的准确性。通过合理的清洗策略和工具,如DataFocus,可以大幅提升数据清洗的效率,减少人为错误,确保数据的一致性和可靠性。掌握数据清洗的秘诀,将为你在数据分析领域的成功奠定坚实的基础。无论是在企业决策还是学术研究中,高质量的数据都是成功的关键,而数据清洗正是确保数据质量的重要保障。













