数据挖掘,作为一个近年来蓬勃发展的领域,已经成为各行各业获取竞争优势的关键工具之一。从金融、医疗、零售到社交媒体,数据挖掘不仅帮助企业更好地理解用户需求,还能在海量信息中提炼出潜在的规律和趋势。在这篇博客文章中,我将分享我在数据挖掘领域的实验心得,揭示数据背后的秘密,并介绍一些帮助提升数据处理效率的工具,例如 DataFocus数仓 和 DataSpring。

数据挖掘:打开数字世界的宝藏
数据挖掘是从大量数据中提取出有用信息的过程,它涉及到统计学、机器学习和数据库技术的综合应用。随着信息技术的飞速发展,越来越多的数据涌入企业系统,但如何有效地从这些数据中提取价值,仍然是许多公司面临的一大挑战。数据挖掘不仅仅是寻找模式,它还包含了数据清洗、数据转换、数据建模等多个步骤。
数据挖掘的核心过程
在进行数据挖掘之前,我们需要了解其基本的流程和关键步骤:
-
数据预处理 数据预处理是数据挖掘过程中最重要的一步。原始数据通常不完美,可能包含缺失值、噪音、重复数据等问题。通过数据清洗,我们可以对数据进行标准化、去重和填补缺失值,为后续分析打下良好的基础。
-
数据探索性分析(EDA) 数据探索性分析通过可视化手段和统计分析方法,帮助我们更好地理解数据的分布、特征和潜在模式。通过EDA,可以快速识别数据中的异常值,检测不同特征之间的关系,为建模提供有价值的见解。
-
建模与算法选择 根据数据的特点,选择适合的算法进行建模。例如,如果目标是预测未来的趋势,可以选择回归分析;如果需要从数据中识别出隐藏的模式,则可以选择聚类算法。在这一阶段,通常需要使用机器学习算法,如决策树、随机森林、K-近邻(KNN)和支持向量机(SVM)等。
-
模型评估与优化 评估模型的准确性和鲁棒性是数据挖掘中至关重要的步骤。通过交叉验证和误差分析,我们可以识别出模型的缺陷,并进行优化。这一过程有助于提高模型的泛化能力,避免过拟合现象。
-
模型部署与应用 一旦我们完成了模型的训练和优化,就需要将其应用到实际的业务场景中。这通常需要将模型与现有的业务流程系统结合,以提供实时的数据分析支持和决策建议。
数据背后的秘密:挖掘实验心得
挖掘实验的挑战
在我的数据挖掘实验中,最大的挑战之一是如何高效地管理和处理海量数据。在处理大规模数据时,传统的数据处理方法常常显得捉襟见肘,尤其是在进行数据整合时,来自不同源的数据格式不统一、数据质量不一致等问题层出不穷。为了有效地应对这些问题,我发现 DataFocus数仓 和 DataSpring 两款工具在我实验中发挥了巨大的作用。
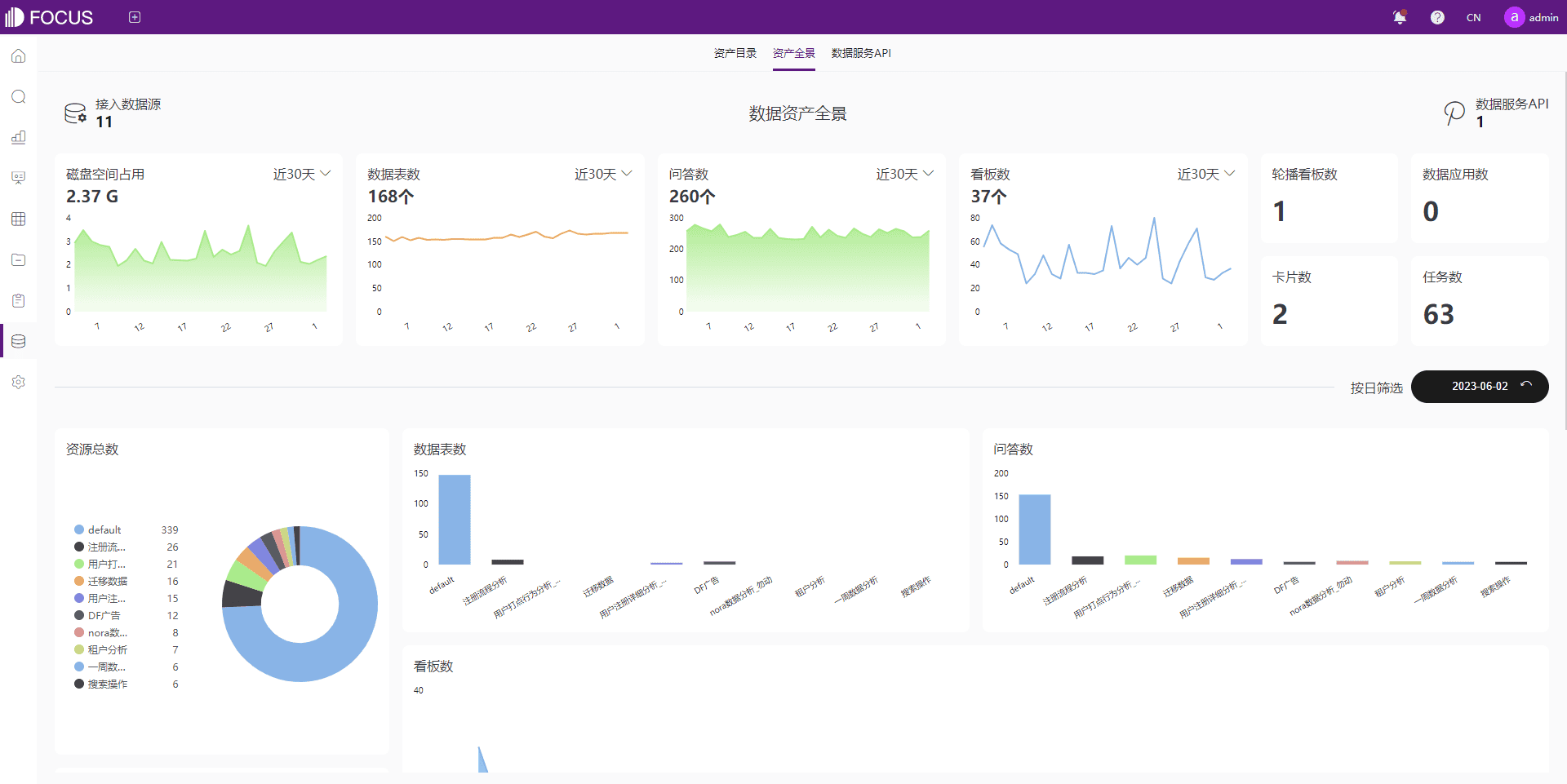
DataFocus数仓 是一款功能强大的数据仓库管理工具,它提供了从数据接入到数据处理、数据分析的全链路解决方案。特别是在处理跨多个数据库的数据时,它的中间表处理和元数据管理功能可以确保数据的统一性和完整性,帮助我更高效地进行数据整合和分析。
DataSpring 则是一款流式数据处理工具,它的 Log-based Change Data Capture(日志增量捕获)技术,可以帮助我实时地获取和处理增量数据。这个功能非常适合需要实时监控和数据同步的场景,在实验中,我能够借助 DataSpring 将不同数据库之间的增量数据同步和转换工作自动化,提高了工作效率,降低了出错的可能性。
数据清洗:揭开数据的面纱
数据清洗是数据挖掘中最耗时的一部分,但它也是最为关键的一步。在我的实验中,数据清洗不仅仅是去除无效数据,更重要的是确保数据的质量和一致性。例如,某些用户行为数据可能存在缺失的情况,而我们无法仅仅删除这些记录,因为这样会导致信息丢失。因此,我通常采用插值法或者均值填充的方法来填补缺失值。
在处理重复数据时,我借助了 DataFocus数仓 的数据血缘管理功能,能够追踪每一条数据的来源和变动历史。这样一来,我能够快速识别出哪些数据是重复的,并进行合理的合并和去重,确保分析结果的准确性。
模式识别与机器学习:发现数据的规律
数据挖掘的核心之一就是从数据中识别潜在的模式和规律。在我的实验中,我应用了多种机器学习算法,如聚类算法、分类算法和回归分析,以便找到数据中的内在联系。
例如,在分析客户购买行为时,我使用了 K-均值聚类算法来将客户分群。通过这种方法,我能够识别出不同群体的消费特点,并为营销策略的制定提供数据支持。借助 DataSpring 的增量数据同步功能,我能够实时更新客户群体的数据,保证分析结果的时效性和准确性。

模型部署与实时监控
模型的部署与实时监控也是我实验的一个重要环节。在将模型应用到实际业务场景中时,我需要确保模型能够实时接收新的数据并进行预测。这里,DataSpring 的实时数据处理功能帮助我解决了这个问题。通过流式处理,我能够实时获得来自不同数据源的更新数据,并将其传递到模型中进行预测和决策。
数据的实时监控也是至关重要的。为了确保模型的持续有效性,我定期对模型进行评估,并根据新的数据调整模型的参数。这不仅能够提高模型的准确性,还能防止随着时间推移,模型的效果逐渐下降。
数据挖掘的未来趋势
随着技术的不断进步,数据挖掘将进入一个新的阶段。未来,数据挖掘将更加注重实时性和自动化。通过 DataFocus数仓 和 DataSpring 这样的工具,企业可以更高效地管理和分析数据,快速获取有价值的信息,做出更加精准的决策。
随着人工智能和深度学习技术的不断发展,数据挖掘的能力将进一步提升。未来的挖掘算法将更加智能,能够从数据中挖掘出更加复杂和深层次的规律。企业将能够通过更先进的技术手段,更加精准地预测市场趋势和客户需求,提升竞争力。
结语
通过多次的数据挖掘实验,我深刻体会到数据不仅仅是数字的堆积,它背后蕴藏着巨大的潜力。通过有效的工具和方法,我们可以从这些数据中挖掘出价值,为业务决策提供强有力的支持。无论是数据的清洗、建模,还是实时监控与部署,借助 DataFocus数仓 和 DataSpring 等工具,都能帮助我们实现数据处理的自动化和高效化,为企业带来更多的商业价值。
如果你也希望提升你的数据挖掘能力,或者在日常的数据处理工作中遇到瓶颈,不妨尝试一下这些强大的工具,帮助你更好地挖掘数据背后的秘密,解锁未来的商业机会。













