探索泰迪杯:数据挖掘的奥秘
数据挖掘是当今信息时代的核心技术之一。它帮助企业通过深度分析海量数据,洞察隐藏的商业机会与潜在风险。近年来,随着各类竞赛的推动与数据技术的进步,泰迪杯作为一项知名的数据科学竞赛,成为了数据挖掘领域的一个重要标杆。本文将深入探讨泰迪杯的本质及其在数据挖掘技术上的运用,并结合实际产品如DataFocus数仓和DataSpring,分析如何通过先进的工具与技术,提升数据挖掘的效率和准确性。
泰迪杯,作为数据科学和机器学习领域的经典比赛之一,不仅汇聚了来自世界各地的顶尖数据科学家和技术人才,更推动了数据挖掘技术的发展与应用。在比赛过程中,参赛者需要从海量数据中提取出有价值的信息,运用先进的算法模型进行分析预测。这不仅考验选手的技术能力,还考验了他们如何高效处理数据、优化数据流,并最终为问题提供准确的解决方案。因此,了解数据的采集、处理、存储与分析等全过程,对于参与泰迪杯或从事数据挖掘工作的专业人士来说,至关重要。
数据挖掘的基本流程与挑战
数据挖掘是一个高度复杂的过程,涉及从数据预处理到模型建立,再到结果评估的多个环节。数据采集和清洗是数据挖掘过程中至关重要的一步。数据来源通常包括各种数据库、日志文件、API接口等,而这些数据往往存在格式不统一、缺失值或异常值等问题,需要通过专门的工具进行预处理和清洗。数据存储是一个关键环节,数据仓库的设计直接影响到后续的分析效率和模型的准确性。
数据分析与建模是数据挖掘的核心部分。在这个阶段,数据科学家通常会使用机器学习、深度学习等算法对处理后的数据进行建模,通过分类、回归、聚类等方式进行预测和决策。模型评估和优化则是确保挖掘结果具备实际应用价值的必要步骤。这一过程中,如何高效地管理与分析数据,如何从海量数据中提取出最有价值的信息,成为了数据挖掘成功的关键。
如何高效实现数据挖掘:数据工具的作用
在泰迪杯这类数据竞赛中,参赛者面临的数据量庞大且复杂,如何高效管理和处理数据,成为了影响最终成绩的一个重要因素。为了确保数据处理的高效与准确,许多企业和数据科学家选择使用专业的数据工具和平台,这些工具能够帮助他们在数据清洗、存储和分析的过程中提升工作效率。

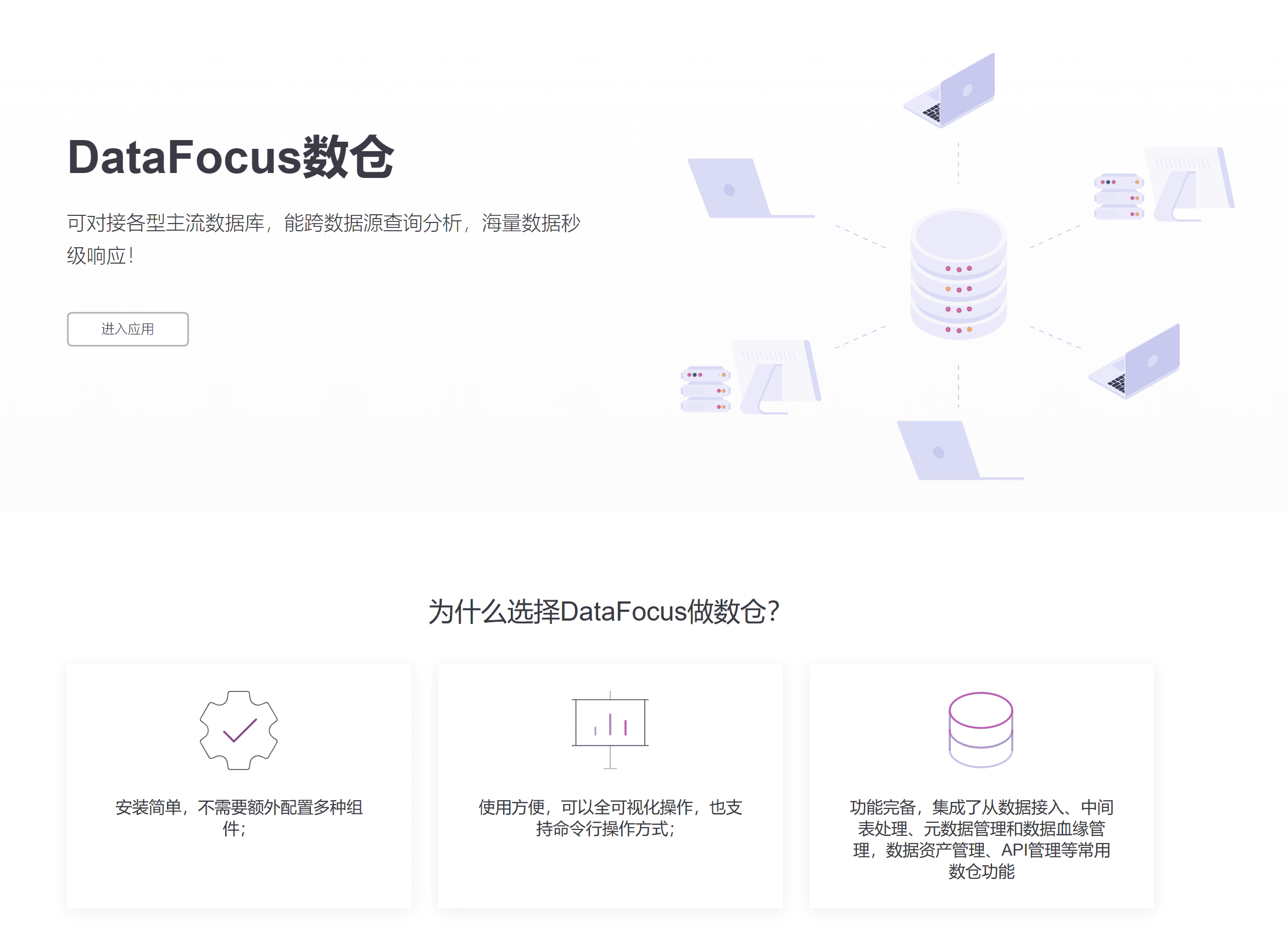
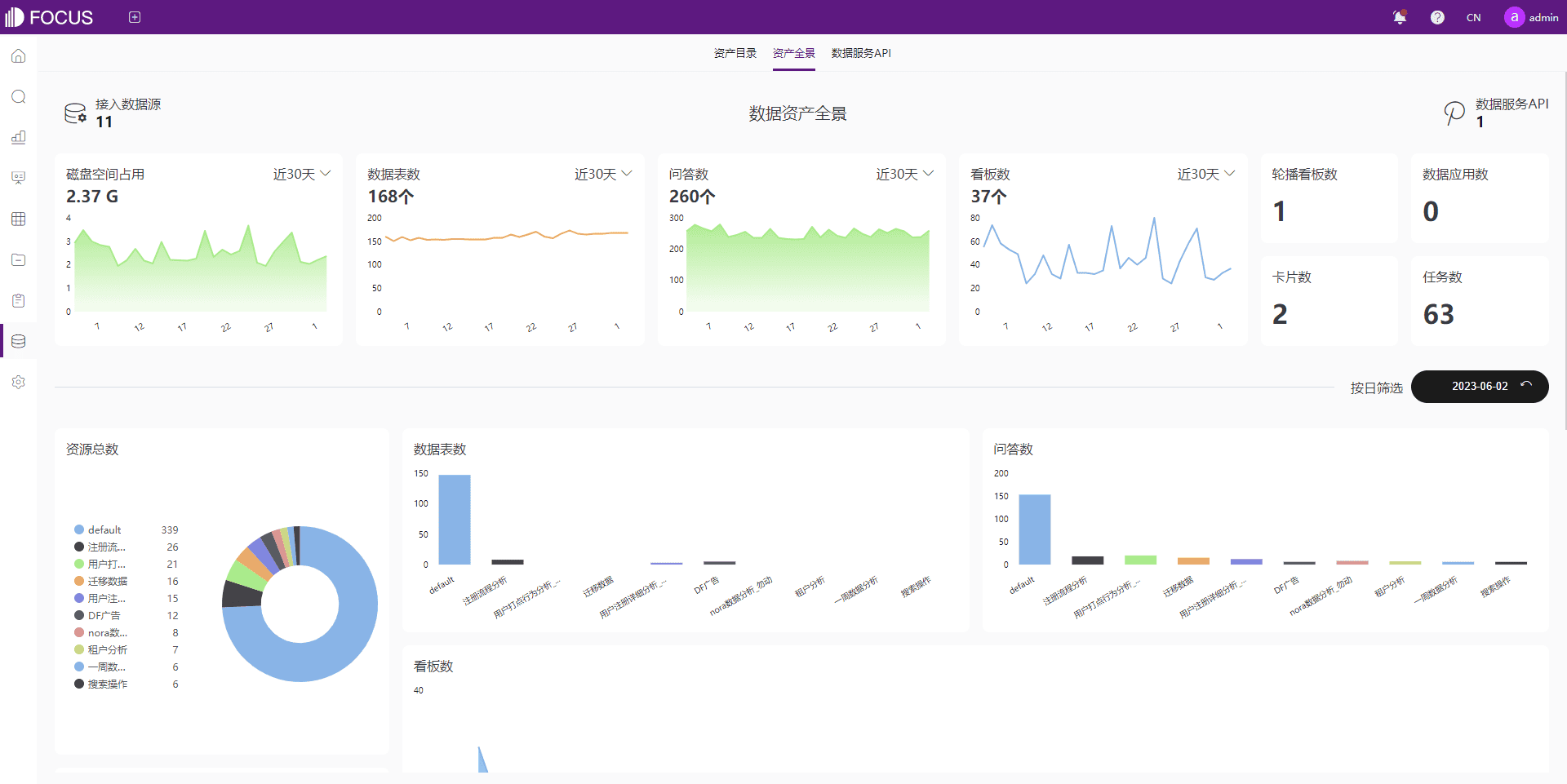
以DataFocus数仓为例,它为企业提供了一个全链路的数据管理平台,涵盖了数据接入、中间表处理、元数据管理、数据血缘管理、数据资产管理等多个方面。特别是在数据接入和处理过程中,DataFocus数仓支持多种主流数据库的对接,并能够确保数据的完整性与一致性,极大地简化了数据预处理与存储的工作。对于大中型企业而言,DataFocus数仓不仅能帮助构建高效的数据底座,还能通过数据血缘管理,帮助用户追溯数据流动的全过程,为数据挖掘提供有力保障。
随着实时数据分析需求的不断增长,DataSpring作为一款基于流式架构的ETL工具,解决了实时数据同步与增量处理的问题。采用基于日志的增量数据获取技术(Log-based Change Data Capture),DataSpring能够高效地支持各种数据库(如Oracle、MySQL、SQL Server、PostgreSQL)以及API数据的实时同步与转换。这种技术使得在数据量巨大且变化频繁的情况下,数据的实时处理与更新变得更加简便和准确。对于参与数据竞赛的选手或企业用户来说,DataSpring提供的自动化数据流转功能,能够帮助他们快速构建数据分析模型,提高数据处理效率,从而为更精确的分析与预测提供支持。
泰迪杯中的数据挖掘技术应用实例
在泰迪杯这类数据科学竞赛中,选手需要快速对数据进行预处理和清洗,然后应用合适的算法进行建模。由于比赛中提供的数据集往往非常庞大且复杂,如何高效地进行数据处理、存储与分析,成为了参赛者的一大挑战。这里,DataFocus数仓和DataSpring等工具就发挥了至关重要的作用。
例如,在某一届泰迪杯中,参赛者面对的数据来源多样,包括历史数据、日志数据、以及从不同API接口抓取的数据。传统的手动数据处理不仅费时费力,而且容易出现数据丢失或错误。在这种情况下,DataFocus数仓的多数据库接入功能大大提升了数据采集的效率,而其强大的数据血缘管理功能帮助选手清晰了解数据的流向与变化,有助于准确定位数据异常问题。与此DataSpring的实时数据同步和增量更新功能,使得选手能够在比赛过程中实时获取最新数据,及时调整模型与策略,提高了模型的准确性和时效性。
未来的数据挖掘趋势与挑战
尽管数据挖掘技术已经取得了显著进展,但随着数据量的不断增加和应用场景的日益复杂,数据挖掘面临的挑战依然巨大。从数据的采集、处理、存储到分析,如何在保证数据质量的前提下提高数据处理速度,如何通过智能化的工具与算法,发现更具商业价值的洞察,仍然是企业和数据科学家需要面对的重大课题。
随着人工智能、物联网等技术的崛起,数据的来源将更加多样,数据的结构也将变得更加复杂。在这种情况下,如何有效地管理与分析这些异构数据,成为了未来数据挖掘技术发展的一大重点。DataFocus数仓与DataSpring等创新工具,正是为了应对这一挑战,提供了更加智能、高效的数据管理和处理方案。
结语
泰迪杯不仅是一项竞赛,更是数据科学与数据挖掘技术不断发展的一个缩影。在未来,随着技术的不断进步,数据挖掘的应用将更加广泛与深入。而如何高效地处理、存储和分析数据,如何利用先进的工具与技术,提高数据挖掘的准确性与时效性,将成为数据科学家和企业面临的主要挑战。借助像DataFocus数仓和DataSpring这样的专业工具,企业和数据科学家能够在复杂的赛场或实际应用中脱颖而出,赢得数据分析的胜利。













