DataSpring是一款基于最新流式架构的ETL工具,采用基于日志的增量数据获取技术( Log-based Change Data Capture ),支持异构数据之间丰富、自动化、准确的语义映射构建,同时满足实时与批量的数据处理。 支持各种主流数据库如 Oracle、MySQL、SQL Server、PostgreSQL 以及API数据的增量同步和转换。
在当今大数据时代,数据处理变得越来越重要。然而,数据的质量往往会影响到分析结果的准确性。因此,在进行数据分析前,我们需要花费大量时间和精力对数据进行清洗和预处理。这也是为什么DataSpring被广泛应用于多个应用场景中的原因。
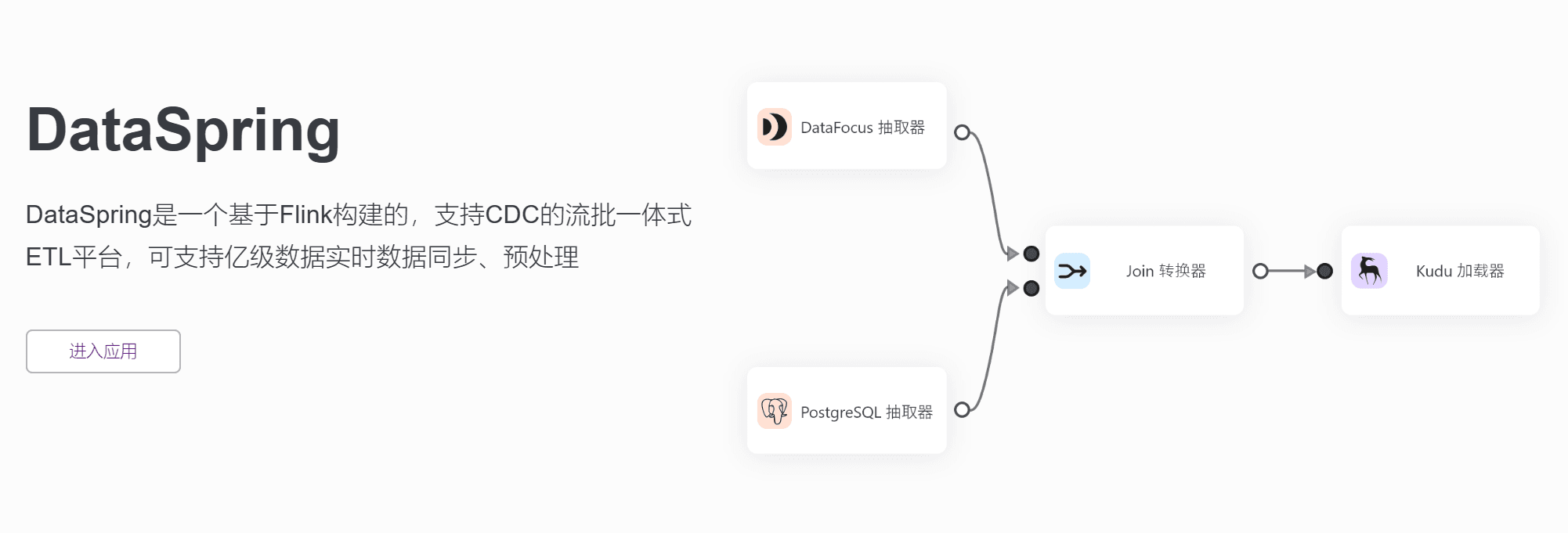
首先,它可以支持亿级别的数据同步和预处理。通过使用CDC技术,DataSpring可以从不同的数据源中抽取出增量数据,并将其实时同步到目标系统中。这可以帮助用户更快地对数据进行处理和分析,并及时获得数据洞察。
其次,该工具支持多种数据源,包括常用关系型数据库和API数据。它还支持定时任务完成批处理任务和基于CDC技术的实时流式数据接入。用户可以通过预置公式实现类似Excel函数的数据转换。对于复杂的数据处理逻辑,DataSpring还支持用户自定义基于Python代码的UDF算子进行处理。
除此之外,此工具还提供了操作日志查询、用户管理等通用模块,方便用户进行管理。DataSpring与DataFocus无缝集成,在DFC会员中心实现单点登录功能。在联合部署之后,可以实现无缝的产品使用体验。
通过这些特性,DataSpring可以帮助用户更轻松地进行数据预处理,提高数据质量和准确性,并且可以应用于多个应用场景中。下面我们来详细介绍一下它的具体功能。
首先是数据接入。DataSpring支持常用关系型数据库数据接入,也支持API数据接入。对于不同的数据源,DataSpring可以进行自动化的语义映射构建,从而实现异构数据之间的丰富、自动化、准确的转换。这使得用户可以更加轻松地将不同类型的数据源连接起来进行处理和分析。
其次是批处理任务。DataSpring支持定时任务完成批处理任务,可以根据用户需求设置不同的参数,例如间隔多久执行、指定时间执行、周期循环执行等。这可以帮助用户更好地管理和控制数据处理流程。
第三是流处理任务。基于CDC技术的实时流式数据接入,是DataSpring的又一大特点。通过这种方式,DataSpring可以从不同的数据源中抽取出增量数据,并将其实时同步到目标系统中。这大大提高了数据处理的效率和准确性。
第四是公式转换。通过预置公式,DataSpring可以实现类似Excel函数的数据转换。这使得用户可以更加灵活地对数据进行转换和处理,从而获得更准确的数据洞察。此外,对于复杂的数据处理逻辑,DataSpring还支持用户自定义基于Python代码的UDF算子进行处理。
最后是定时任务。配置好的任务流支持做成定时任务,可以根据用户需求设置不同的参数,例如间隔多久执行、指定时间执行、周期循环执行等。这也是DataSpring的一大特点,它可以帮助用户更好地管理和控制数据处理流程。
在使用DataSpring过程中,还需要注意垃圾进,垃圾出。为了获得准确的数据洞察,分析师们往往要将80%的精力放到数据预处理的工作上面。而DataSpring正是为了解决这一问题而生,它支持异构数据之间丰富、自动化、准确的语义映射构建,同时满足实时与批量的数据处理。具有更高的吞吐和更低的延时,使得数据和计算不分离,应用只需本地访问即可获取数据,从而提高数据质量和准确性。
总之,DataSpring是一款强大的ETL工具,可以帮助用户更快更准确地进行数据预处理,提高数据质量,获得准确的数据洞察。该工具支持多种数据源,包括常用关系型数据库和API数据,可以进行自定义的数据处理逻辑,并支持实时和批量处理。它被广泛应用于多个应用场景中,用户可以通过私有化部署来轻松使用并管理该工具。













