随着大数据时代的到来,数据处理和分析成为企业获取商业价值的关键步骤。然而,数据预处理却是数据分析中的重要瓶颈。为了获得准确的数据洞察,分析师们往往要将 80% 的精力放到数据预处理上。这使得如何提高数据预处理效率成为许多企业的痛点。
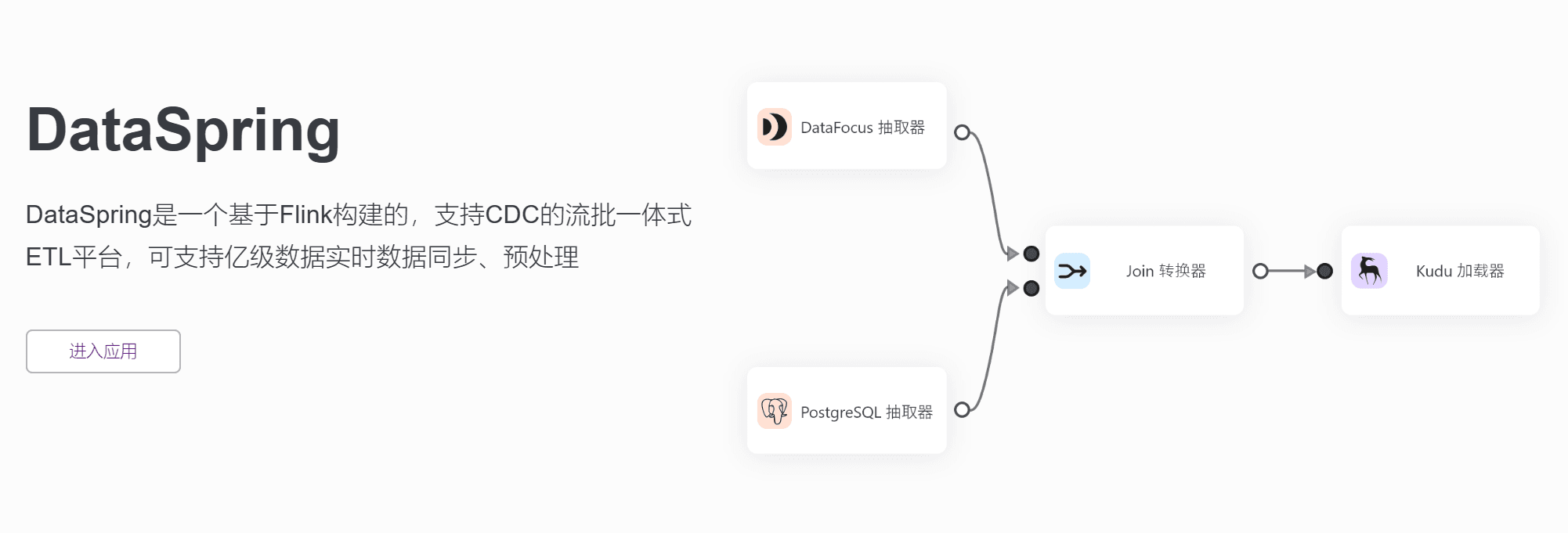
针对这个问题,DataSpring应运而生,作为一款基于Flink构建的、支持CDC的流批一体式ETL平台,它拥有众多优势,在亿级数据实时同步和预处理方面表现突出。
DataSpring采用基于日志的增量数据获取技术(Log-based Change Data Capture),能够支持异构数据的丰富、自动化、准确的语义映射和实时与批量的数据处理。除此之外,DataSpring还可以支持各种主流数据库,如Oracle、MySQL、SQL Server、 PostgreSQL 和 API 数据的增量同步和转换。这意味着DataSpring可以支持亿级数据的实时同步和预处理,从源头上避免垃圾数据进入系统。因此,分析师们就可以省去大量人力在数据预处理上的开支,效率也会相应提高。
DataSpring架构对传统架构进行了巧妙的优化,传统架构需要读写远程事务型数据库,但在事件驱动应用中,数据和计算并没有分离。相反,应用只需本地访问即可获得所需数据,具有更高的吞吐和更低的延迟。这样的架构优化可以使得 DataSpring 的性能更加强劲,在实时任务、业务数据加载到数据仓库、监控大屏等场景下,DataSpring 能够胜任多种任务。
在功能方面,DataSpring支持常用关系型数据库数据接入、API 数据接入。它还可以通过预置公式来实现类似 excel 函数的数据转换,并针对复杂数据处理逻辑,还支持自定义基于 Python 代码的 UDF 算子进行处理。此外,DataSpring 还配置好的任务流支持周期循环执行或指定时间执行等特有功能。
DataSpring管理界面提供操作日志查询、用户管理等通用模块,并与 DataFocus 无缝集成,支持 DFC 会员中心的单点登录功能。客户可以以私有云方式部署 DataSpring,简单易操作,避免了企业内部数据泄漏的隐患,同时保持数据的安全性。
从使用方面看,DataSpring能够提高数据预处理的效率,减轻分析师的工作压力, 时间成本和金钱成本都会相应的下降。因此,在实时计算、业务数据加载到数据仓库和事件驱动型应用等场景中,DataSpring 的表现优异。DataSpring充分体现了其在数据处理方面所扮演的重要角色,为企业提供了精确、高效的数据支持,真正助力企业获取商业价值。

综上所述,随着大数据及人工智能应用需求的发展日益增长,DataSpring这种ETL工具也越来越需要被广泛地应用于各个领域。通过DataSpring,分析师们锁定数据的价值洞察点,将极大地促进企业转型升级,达到跑得更快的目标。













