在现代商业环境中,数据已成为企业最宝贵的资产之一。随着科技的发展,企业拥有了前所未有的机会来收集、分析并利用各种类型的数据。如何高效地挖掘这些数据的价值,成为了许多企业面临的挑战。而数据挖掘的金矿并不仅仅局限于某一种特定的数据来源,恰恰相反,掌握多样化的数据来源,才能更好地解锁数据的潜力,实现更具洞察力的决策。
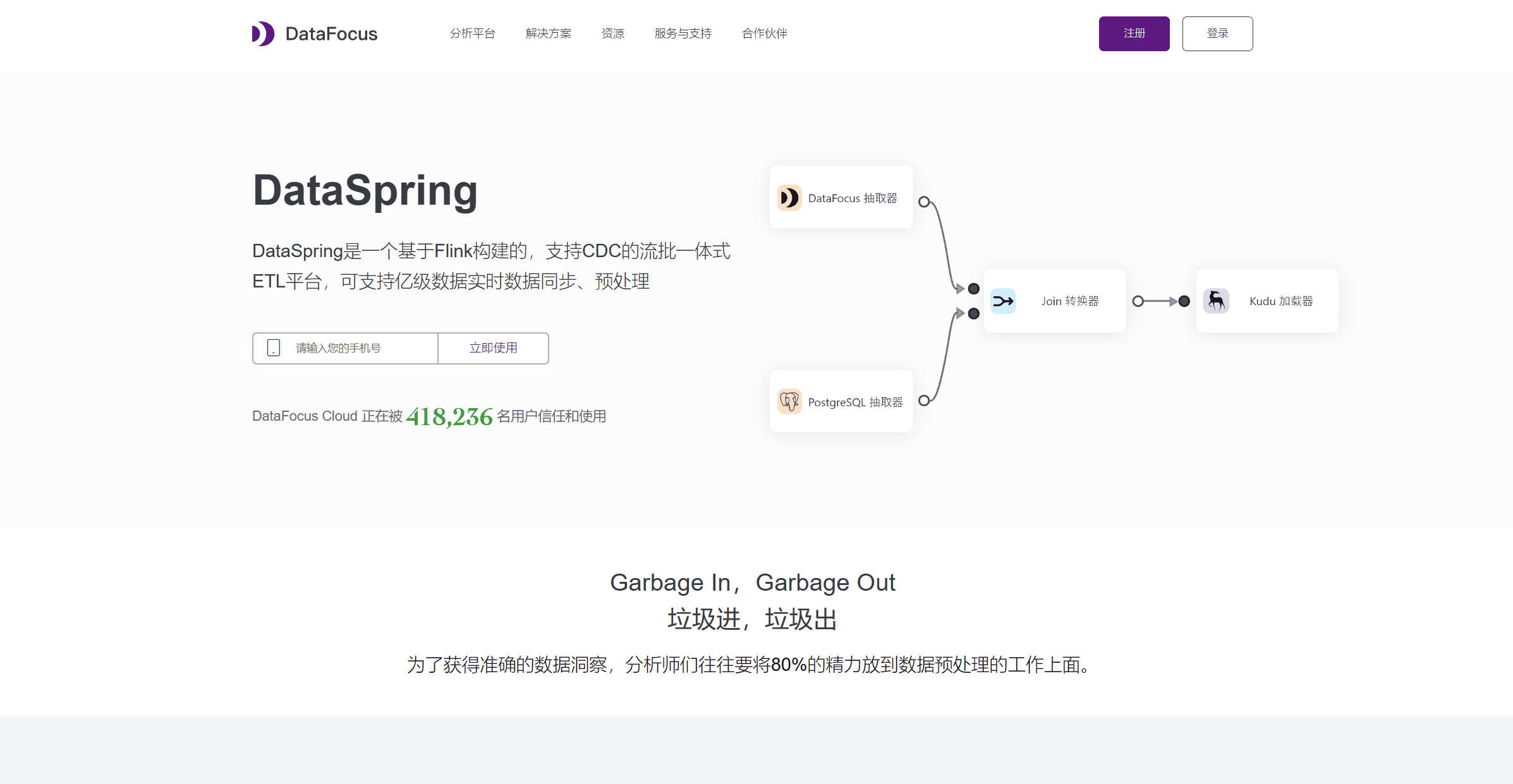
在本文中,我们将深入探讨如何一网打尽各类数据来源,挖掘数据中的金矿,并介绍一些有力的数据工具,比如DataFocus数仓和DataSpring,它们能够帮助企业在数据接入、转换与管理过程中实现高效操作,为数据分析提供强大的支持。
一、数据挖掘的金矿:多源数据的整合
1.1 什么是数据挖掘?
数据挖掘(Data Mining)是一种从大量数据中自动或半自动地发现有用模式和知识的技术。通过数据挖掘,企业可以从原始数据中提取出潜在的趋势、规律和洞察,帮助决策者制定更加明智的策略。
数据挖掘的过程通常包括以下几个步骤:
- 数据预处理:对原始数据进行清洗、格式化和归一化等处理。
- 数据探索:通过统计分析、可视化等方法,对数据进行初步的分析。
- 建模与分析:利用机器学习和算法模型进行更深层次的数据分析。
- 知识提取:从数据中发现新的规律、趋势和预测信息。
数据挖掘的难度往往与数据的来源多样性有关。企业的数据可能来源于多个不同的渠道,包括结构化数据、非结构化数据、实时数据和历史数据等。如何有效地整合和利用这些不同来源的数据,成为了数据挖掘的核心挑战之一。
1.2 各类数据来源:丰富多样的数据源
在企业的数据挖掘过程中,数据的来源可以非常多样。以下是常见的几类数据来源,每一类数据都可能是企业宝贵的“金矿”。
1.2.1 结构化数据
结构化数据是指那些已经被组织成表格、数据库等格式的数据。它通常存储在关系型数据库中,包含了表、字段、记录等清晰定义的结构。常见的结构化数据来源包括:
- 关系型数据库:例如 MySQL、Oracle、SQL Server、PostgreSQL 等。
- 数据仓库:企业的数据仓库通常包含了从各个业务系统中抽取并整合的数据。
结构化数据易于分析,可以使用 SQL 等语言进行高效查询和处理。但随着数据量的增加,如何快速接入和处理这些数据,尤其是在大中型企业中,成为了重要的问题。
1.2.2 非结构化数据
非结构化数据是指那些没有固定格式、没有明确组织的数据。它们包括文字、图片、视频、音频等形式,通常出现在社交媒体、网页、邮件等地方。常见的非结构化数据来源包括:
- 社交媒体:如微博、微信、Facebook、Twitter 等平台上的用户行为数据。
- 文本数据:如企业的客户服务记录、博客文章、论坛帖子等。
- 多媒体数据:如视频、图片和音频文件。
非结构化数据的分析需要较为复杂的自然语言处理(NLP)技术和图像识别技术,但它们蕴含着丰富的商业价值,能够帮助企业洞察消费者的行为、情感以及市场趋势。
1.2.3 实时数据
实时数据是指能够即时获取和处理的数据,通常来自于传感器、日志、网站访问等流式数据源。常见的实时数据来源包括:
- IoT设备:如智能设备、传感器等生成的实时数据。
- 日志数据:例如服务器的访问日志、交易日志等。
- 网站行为数据:例如网站流量、用户点击、页面停留等实时数据。
实时数据对于企业来说,尤其在需要快速反应和决策的场景下尤为重要。如何保证数据的低延迟、实时更新,并快速进行分析处理,是一个关键挑战。
1.2.4 外部数据
外部数据是指那些来源于公司外部的数据,通常通过开放数据平台、第三方服务或合作伙伴提供。常见的外部数据来源包括:
- 公共数据集:如政府发布的统计数据、研究机构发布的数据集等。
- 第三方数据提供商:例如市场研究公司、社交媒体分析公司等提供的数据。
外部数据能够为企业提供更广泛的视角和背景,帮助企业进行市场预测、竞争分析和趋势判断。
二、如何高效整合各类数据来源?
对于企业而言,如何将各类数据来源整合在一起,并从中提取出有价值的信息,是数据挖掘的关键。为了实现这一目标,企业需要借助一系列数据处理工具和技术。
2.1 数据接入与集成:打破数据孤岛
不同类型的数据通常存储在不同的系统中,企业往往面临数据孤岛的问题。这意味着数据无法跨系统互通,导致信息孤立、管理困难、效率低下。
为了解决这一问题,企业可以采用数据仓库技术。DataFocus数仓就是一个能够高效接入各种主流数据库和数据源的工具,支持包括关系型数据库(如 MySQL、Oracle、SQL Server、PostgreSQL)以及API数据在内的多种数据源对接。通过DataFocus数仓,企业可以将来自不同系统的数据统一集成到一个数据平台上,方便后续的处理和分析。
2.2 数据清洗与转换:保证数据质量
不同来源的数据往往存在格式不一致、缺失值、重复数据等问题。因此,数据清洗与转换是数据挖掘中不可或缺的一部分。DataSpring作为一款基于流式架构的ETL工具,能够帮助企业进行高效的数据清洗和转换。它支持基于日志的增量数据获取技术(Log-based Change Data Capture),实现了实时与批量数据处理的无缝结合。
通过DataSpring,企业可以实现对异构数据源的自动化和准确的语义映射,确保从各类数据来源中提取的内容能够统一格式、消除冗余并填补缺失,保证数据质量。
2.3 数据分析与挖掘:揭示数据的价值
数据整合并清洗后,企业就可以开始进行深入的分析与挖掘了。通过统计分析、机器学习、数据可视化等方法,企业可以从数据中提取出有价值的知识,帮助决策者制定更精确的策略。
无论是市场分析、客户行为预测、产品优化,还是风险评估,数据挖掘技术都可以为企业提供强有力的支持。通过结合DataFocus数仓和DataSpring的强大数据处理能力,企业能够更加高效地进行数据分析与挖掘,快速获取决策所需的洞察。
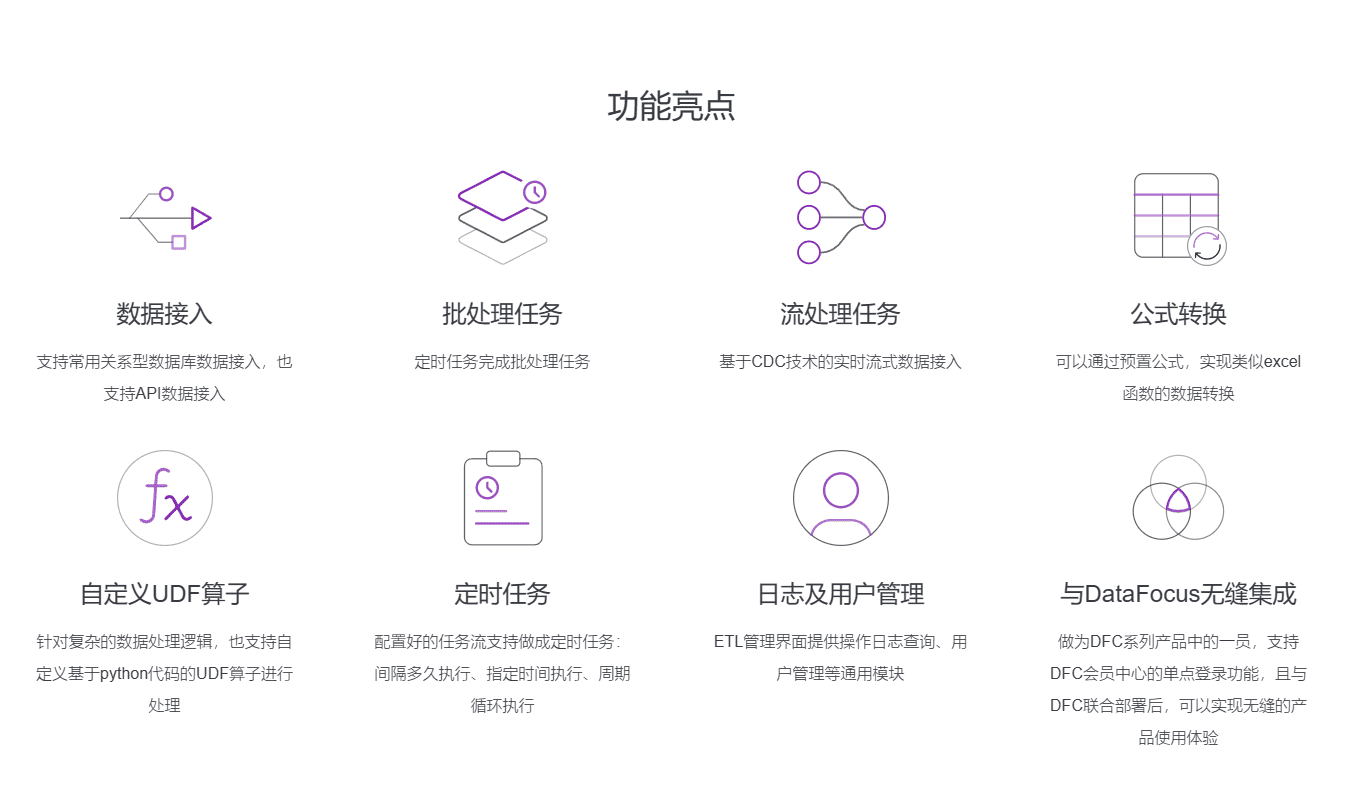
2.4 数据安全与管理:确保数据合规
随着数据量的增加,如何管理和保护企业的数据,尤其是敏感数据,成为了一个重要问题。企业需要确保数据的安全性和合规性,防止数据泄露和滥用。
DataFocus数仓提供了全链路的元数据管理和数据血缘管理功能,帮助企业对数据进行详细的管理与追踪。通过完善的数据资产管理和API管理功能,企业可以清晰地掌握数据的来源、流向和使用情况,确保数据的安全与合规。
三、总结
在数据挖掘的过程中,企业如果能够高效整合来自各个渠道和系统的数据,将能够挖掘出更多的商业价值。通过合理利用DataFocus数仓和DataSpring等工具,企业可以打破数据孤岛,优化数据的清洗与转换过程,提高数据分析的效率和准确性,从而更好地洞察市场和客户需求,提升决策质量。
数据挖掘的金矿就在眼前,关键在于如何将这些多样化的数据源有效整合、管理和分析。只有掌握了这一点,企业才能真正站在数据的最前沿,获得竞争优势,赢得未来。













