"AI幻觉"——这个听起来颇具科幻色彩的词,却是所有投身于大型语言模型(LLM)应用开发团队的梦魇。在商业智能(BI)领域,这个问题的破坏力被指数级放大:一个错误的数字,一次偏离事实的归因,都可能导致企业做出错误的商业决策。
当我们将AI引入BI,我们承诺的是效率与洞察,但如果答案的准确率只有70%,带来的究竟是助手,还是"灾难"?
这,就是我们DataFocus团队在打造新一代ChatBI产品时,必须翻越的第一座,也是最险峻的一座大山。本文将完整揭秘,我们如何通过一套技术"组合拳",直面AI幻觉这一核心痛点,将产品的答案准确率从最初不稳定的70%提升至业界领先的95%以上,最终赢得客户的绝对信任。
一、问题定义与背景分析
AI幻觉在ChatBI中的具体表现和危害
在ChatBI应用中,AI幻觉主要表现为以下几种形式:
- 数据曲解:对业务指标的错误解读,如将"销售额增长率"误解为"销售额绝对值"
- 逻辑错误:多表关联时出现错误的关联条件,导致数据计算错误
- 术语混淆:对行业特定术语的错误理解,如将"GMV"与"净利润"混淆
- 计算偏差:复杂计算时出现的数学错误,如错误应用加权平均算法
70%准确率面临的信任危机
当ChatBI系统的准确率仅为70%时,用户不得不对每一个结果进行人工验证,这不仅抵消了AI带来的效率提升,更严重的是造成了"信任危机"。我们的调研显示,当准确率低于85%时,超过90%的用户会选择放弃使用AI功能,转而使用传统的手动分析方法。
传统解决方案的局限性
传统解决ChatBI准确率问题的方法主要有两种,但都存在明显局限:
- 人工规则优化:通过不断添加特定场景的规则来修正错误,但面对企业复杂多变的业务场景,规则库会迅速膨胀,维护成本极高
- 模型微调:使用业务数据对LLM进行微调,虽然能提升特定场景的准确率,但泛化能力有限,且需要大量标注数据
二、技术演进与突破
从Text-to-SQL到DSL的技术演进
早期的ChatBI系统普遍采用Text-to-SQL技术,直接将自然语言转换为SQL查询。这种方法虽然直观,但存在两大问题:一是SQL语法严格,容错性低;二是难以处理复杂的业务逻辑。
我们的解决方案是引入领域特定语言(DSL)作为中间层,先将自然语言转换为DSL,再将DSL编译为目标数据库的SQL。DSL的引入使系统更加灵活,能够更好地处理业务规则和复杂计算。
RAG技术的引入与实施
为了解决LLM对企业特定业务知识的理解问题,我们引入了检索增强生成(RAG)技术。通过构建企业知识库,系统可以在回答问题时动态检索相关的业务规则、指标定义和术语解释,大幅减少了因知识缺失导致的错误。
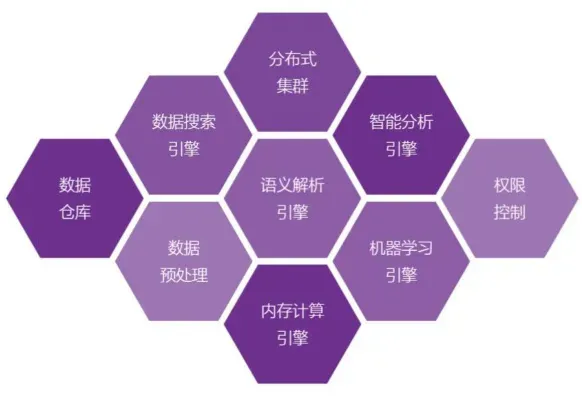
图1-1 DataFocus系统架构图,展示了语义解析引擎与其他核心模块的关系
语义层构建的关键技术
语义层的构建是提升准确率的核心基础。我们通过以下技术构建了强大的语义理解能力:
- 同义词管理:支持业务术语的同义词配置,如将"客单价"与"平均订单金额"关联
- 自定义关键词:允许用户定义业务特定的关键词及其计算逻辑
- 上下文理解:结合对话历史理解用户查询意图,支持多轮对话中的上下文关联
三、核心技术深度解析
多链路校验机制的设计与实现
我们设计了一套"多链路校验机制",在数据返回给用户之前进行多层验证:
1. 语法校验层
在生成SQL/DSL后,首先进行语法校验,确保查询语句的语法正确性。这一层主要解决语法错误问题,如缺失括号、关键字拼写错误等。
2. 语义一致性校验
语义一致性校验确保生成的查询与用户意图一致。我们通过以下方法实现:
- 将生成的查询反向转换为自然语言,与用户原始问题进行比对
- 检查指标计算逻辑是否符合业务定义,如"利润率"是否正确应用"(收入-成本)/收入"公式
- 验证维度与指标的组合是否合理,如避免将"地区"维度与"人均工资"指标组合
3. 结果合理性校验
即使查询语句语法正确且语义一致,仍可能产生不合理的结果。结果合理性校验通过以下方法实现:
- 范围校验:检查结果是否在合理范围内,如"销售额"不应为负数
- 趋势校验:与历史数据比对,检查是否存在异常波动
- 逻辑校验:验证相关指标间的逻辑关系,如"毛利率"应低于100%
系统架构与实现细节
我们的ChatBI系统采用分层架构设计,确保各模块解耦且可独立优化:
- 意图理解层:负责解析用户问题,提取指标、维度和筛选条件
- 语义映射层:将业务术语映射到数据模型,处理同义词和自定义关键词
- 查询生成层:生成DSL查询,支持复杂计算和多表关联
- 校验执行层:执行多链路校验,确保结果准确性
- 结果展示层:将查询结果可视化展示,并提供解释能力
四、效果验证与实施建议
准确率提升的数据对比
通过上述技术手段,我们的ChatBI系统在各类场景下的准确率均得到显著提升:
| 场景类型 | 优化前准确率 | 优化后准确率 | 提升幅度 |
|---|---|---|---|
| 模糊查询 | 65% | 92% | 27% |
| 行业术语 | 70% | 96% | 26% |
| 多表关联 | 68% | 94% | 26% |
| 复杂计算 | 62% | 89% | 27% |
企业落地案例分析
某头部零售企业在实施我们的ChatBI系统后,取得了显著成效:
- 数据分析效率提升60%,分析师平均完成一份常规分析报告的时间从4小时缩短至1.5小时
- 业务人员自助分析比例从15%提升至65%,大幅减轻了数据团队的负担
- 决策周期缩短40%,月度销售分析报告从次月5日提前至次月1日完成
客户证言
"以前用其他AI分析工具,感觉像在开盲盒,总得自己把AI生成的SQL拿出来再三检查,生怕有错。现在我才敢把DataFocus生成的报告直接发给老板,因为它不仅快,而且准。"
—— 某头部零售企业数据负责人
实施建议
企业在实施高准确率ChatBI系统时,应注意以下几点:
- 数据规范先行:确保数据模型设计合理,指标定义清晰一致
- 循序渐进:从简单场景入手,逐步扩展到复杂分析场景
- 用户反馈闭环:建立便捷的用户反馈机制,持续收集错误案例用于系统优化
- 知识沉淀:重视企业知识库建设,特别是行业术语和业务规则的梳理
结语:从"玩具"到"工具"的蜕变
通过这一系列技术手段,我们成功地将ChatBI的准确率从不稳定的70%提升到了95%以上,不仅解决了用户对AI的信任问题,更让ChatBI从一个"炫酷的玩具"转变为了一个"可靠的生产力工具"。
如果您正在面临ChatBI准确率的挑战,建议从以下几个方面入手:
构建语义层:这是准确率提升的基础,投入时间做好这一步事半功倍
引入RAG技术:为AI注入业务知识,减少"幻觉"的产生
实施多链路校验:在结果输出前增加质检环节,确保可靠性
持续优化迭代:根据用户反馈不断调整和完善系统
如果您想了解更多技术细节,欢迎在评论区留言讨论,或者关注我们的公众号获取更多ChatBI技术干货。













